Я пытаюсь изучить ANTLR4, и у меня уже возникли проблемы с моим первым экспериментом.
Цель здесь — научиться использовать ANTLR для подсветки синтаксиса компонента QScintilla. Чтобы немного попрактиковаться, я решил научиться правильно выделять *.ini файлы.
Перво-наперво, для запуска mcve вам понадобится:
- Скачайте antlr4 и убедитесь, что он работает, читайте инструкцию на основном сайте
- Установите среду выполнения python antlr, просто выполните:
pip install antlr4-python3-runtime Сгенерируйте лексер/парсер
ini.g4:grammar ini; start : section (option)*; section : '[' STRING ']'; option : STRING '=' STRING; COMMENT : ';' ~[\r\n]*; STRING : [a-zA-Z0-9]+; WS : [ \t\n\r]+;
запустив antlr ini.g4 -Dlanguage=Python3 -o ini
Наконец, сохраните
main.py:import textwrap from PyQt5.Qt import * from PyQt5.Qsci import QsciScintilla, QsciLexerCustom from antlr4 import * from ini.iniLexer import iniLexer from ini.iniParser import iniParser class QsciIniLexer(QsciLexerCustom): def __init__(self, parent=None): super().__init__(parent=parent) lst = [ {'bold': False, 'foreground': '#f92472', 'italic': False}, # 0 - deeppink {'bold': False, 'foreground': '#e7db74', 'italic': False}, # 1 - khaki (yellowish) {'bold': False, 'foreground': '#74705d', 'italic': False}, # 2 - dimgray {'bold': False, 'foreground': '#f8f8f2', 'italic': False}, # 3 - whitesmoke ] style = { "T__0": lst[3], "T__1": lst[3], "T__2": lst[3], "COMMENT": lst[2], "STRING": lst[0], "WS": lst[3], } for token in iniLexer.ruleNames: token_style = style[token] foreground = token_style.get("foreground", None) background = token_style.get("background", None) bold = token_style.get("bold", None) italic = token_style.get("italic", None) underline = token_style.get("underline", None) index = getattr(iniLexer, token) if foreground: self.setColor(QColor(foreground), index) if background: self.setPaper(QColor(background), index) def defaultPaper(self, style): return QColor("#272822") def language(self): return self.lexer.grammarFileName def styleText(self, start, end): view = self.editor() code = view.text() lexer = iniLexer(InputStream(code)) stream = CommonTokenStream(lexer) parser = iniParser(stream) tree = parser.start() print('parsing'.center(80, '-')) print(tree.toStringTree(recog=parser)) lexer.reset() self.startStyling(0) print('lexing'.center(80, '-')) while True: t = lexer.nextToken() print(lexer.ruleNames[t.type-1], repr(t.text)) if t.type != -1: len_value = len(t.text) self.setStyling(len_value, t.type) else: break def description(self, style_nr): return str(style_nr) if __name__ == '__main__': app = QApplication([]) v = QsciScintilla() lexer = QsciIniLexer(v) v.setLexer(lexer) v.setText(textwrap.dedent("""\ ; Comment outside [section s1] ; Comment inside a = 1 b = 2 [section s2] c = 3 ; Comment right side d = e """)) v.show() app.exec_()
и запустите его, если все прошло хорошо, вы должны получить такой результат:
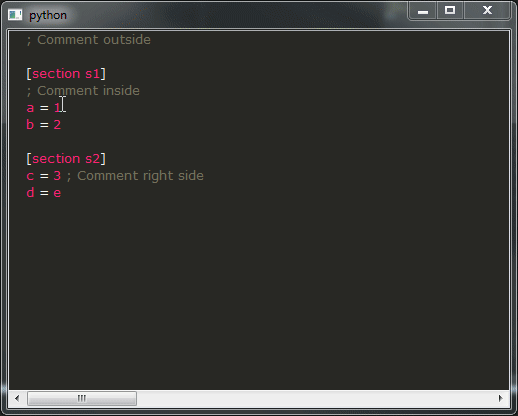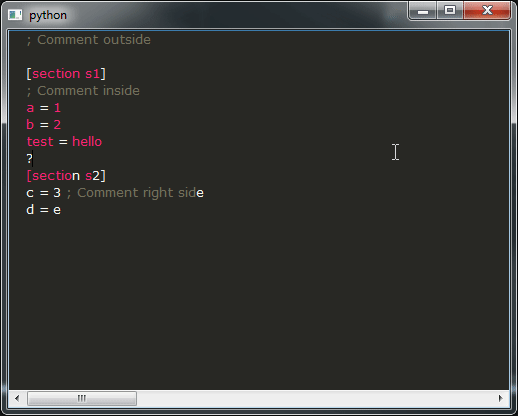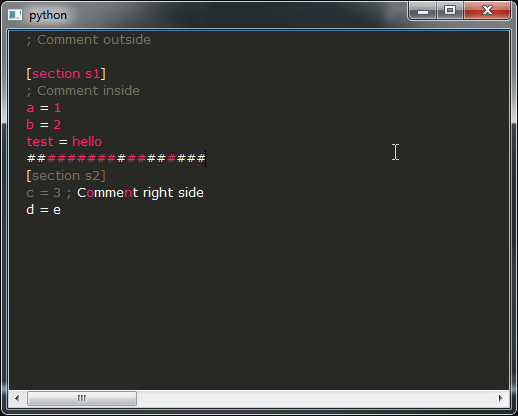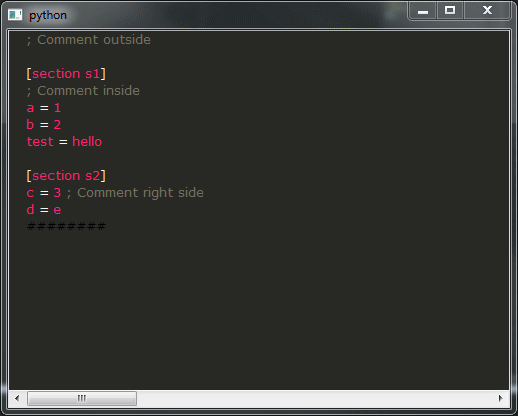
Вот мои вопросы:
- Как видите, результат демонстрации далек от того, чтобы его можно было использовать, вам определенно это не нужно, это действительно беспокоит. Вместо этого вы хотели бы получить такое же поведение, как и все IDE. К сожалению, я не знаю, как этого добиться, как бы вы изменили фрагмент, обеспечивающий такое поведение?
- Прямо сейчас я пытаюсь имитировать выделение, аналогичное снимку ниже:

вы можете видеть на этом снимке экрана выделение по-разному при назначении переменных (переменная = темно-розовый и значения = желтоватый), но я не знаю, как этого добиться, я пытался использовать эту слегка измененную грамматику:
grammar ini;
start : section (option)*;
section : '[' STRING ']';
option : VARIABLE '=' VALUE;
COMMENT : ';' ~[\r\n]*;
VARIABLE : [a-zA-Z0-9]+;
VALUE : [a-zA-Z0-9]+;
WS : [ \t\n\r]+;
а затем изменить стили на:
style = {
"T__0": lst[3],
"T__1": lst[3],
"T__2": lst[3],
"COMMENT": lst[2],
"VARIABLE": lst[0],
"VALUE": lst[1],
"WS": lst[3],
}
но если вы посмотрите на вывод лексирования, вы увидите, что не будет различия между VARIABLE и VALUES, потому что приоритет порядка в грамматике ANTLR. Итак, мой вопрос: как бы вы изменили грамматику/фрагмент, чтобы добиться такого внешнего вида?
