У меня был этот вопрос несколько месяцев. Похоже, мы просто угадали softmax как функцию вывода, а затем интерпретировали ввод softmax как логарифмические вероятности. Как вы сказали, почему бы просто не нормализовать все результаты, разделив их на их сумму? Я нашел ответ в книге по глубокому обучению Гудфеллоу, Бенжио и Курвиль (2016) в разделе 6.2.2.
Скажем, наш последний скрытый слой дает нам z в качестве активации. Тогда softmax определяется как

Очень краткое объяснение
Эксперимент в функции softmax грубо сокращает журнал потерь кросс-энтропии, в результате чего потери становятся примерно линейными по z_i. Это приводит к примерно постоянному градиенту, когда модель ошибочна, что позволяет ей быстро исправляться. Таким образом, неправильный насыщенный softmax не вызывает исчезающего градиента.
Краткое объяснение
Самый популярный метод обучения нейронной сети - это оценка максимального правдоподобия. Мы оцениваем параметры theta таким образом, чтобы максимизировать вероятность обучающих данных (размера m). Поскольку вероятность всего набора обучающих данных является продуктом вероятностей каждой выборки, проще максимизировать логарифмическую вероятность набора данных и, следовательно, сумму логарифмической вероятности каждой проиндексированной выборки. автор: k:

Теперь мы сосредоточимся только на softmax здесь с уже заданным z, поэтому мы можем заменить

где i - правильный класс k-го образца. Теперь мы видим, что когда мы логарифмируем softmax, чтобы вычислить логарифмическую вероятность выборки, мы получаем:

, что для больших различий в z примерно приближается к
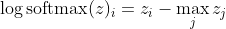
Сначала мы видим здесь линейную составляющую z_i. Во-вторых, мы можем изучить поведение max (z) для двух случаев:
- Если модель верна, то max (z) будет z_i. Таким образом, логарифмическая асимптота правдоподобия равна нулю (то есть вероятность равна 1) с растущей разницей между z_i и другими записями в z.
- Если модель неверна, то max (z) будет другим z_j> z_i. Таким образом, добавление z_i не отменяет полностью -z_j, и логарифмическая вероятность составляет примерно (z_i - z_j). Это ясно говорит модели, что делать для увеличения логарифмической вероятности: увеличивать z_i и уменьшать z_j.
Мы видим, что в общей логарифмической вероятности будут преобладать выборки, модель которых неверна. Кроме того, даже если модель действительно неверна, что приводит к насыщенному softmax, функция потерь не насыщается. Он примерно линейен по z_j, что означает, что у нас примерно постоянный градиент. Это позволяет модели быстро исправляться. Обратите внимание, что это не относится, например, к среднеквадратической ошибке.
Длинное объяснение
Если softmax по-прежнему кажется вам произвольным выбором, вы можете взглянуть на обоснование использования сигмоида в логистической регрессии:
Почему сигмоидальная функция вместо чего-либо еще?
Softmax - это обобщение сигмоида для мультиклассовых задач, обоснованное аналогичным образом.
person
Kilian Batzner
schedule
11.12.2017



