Использование обычного метода наименьших квадратов (OLS) с функцией lm() для оценки уравнения (2) в вопросе привело бы к оценке коэффициентов  ,
, 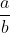 и
и 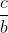 .
.
С другой стороны, использование нелинейного метода наименьших квадратов с функцией nls() для оценки уравнения позволит оценить значения параметров «a», «b» и «c», которые представляют интерес.
Функция nls() (нелинейный метод наименьших квадратов) в R имеет два важных параметра: сначала параметр formula, а затем параметр start. Запуск ?nls в R предоставит некоторые подробности; однако суть в том, что параметр formula принимает выражение нелинейной модели, которую нужно оценить (например, y ~ a / (b + c*x), где «y» и «x» — переменные, а «a», «b» и «c» — интересующие параметры), а параметр start принимает начальные значения интересующих параметров, которые R будет использовать в процессе итерации (поскольку нелинейный метод наименьших квадратов в основном повторяет вычисления до тех пор, пока не будут получены наилучшие значения для параметров).
Ниже приведены шаги:
(i) Получите начальные значения параметров «a», «b» и «c».
Здесь я использовал функцию lm() для оценки коэффициента уравнения (2). Я начал с создания переменных с задержкой для использования в функции.
NB: 'y' относится к '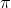 '
'
y_1 = c(NA, head(y, head(y, -1) # variable 'y' lagged by one time period
y_2 = c(c(NA, NA), head(y, head(y, -2) # variable 'y' lagged by two time periods
x_1 = c(NA, head(x, head(x, -1) # variable 'x' lagged by one time period
Итак, для оценки коэффициентов уравнения использовался следующий код:
reg = lm(y ~ y_1 + y_2 + x_1, na.action = na.exclude) # it is important to tell R to exclude the missing values (NA) that we included as we constructed the lagged variables
Теперь, когда у нас есть оценки для  ,
,  и
и  , мы можем продолжить и вычислить значения для 'a', 'b' и 'c' следующим образом:
, мы можем продолжить и вычислить значения для 'a', 'b' и 'c' следующим образом:
B = 1 / reg$coefficients["y_1"] # Calculates the inverse of the coefficient on the variable 'y_1'
A = B * reg$coefficients["y_2"] # Multiplies 'b' by the coefficient on the variable 'y_2'
C = B * reg$coefficients["x_1"] # Multiplies 'b' by the coefficient on the variable 'x_1'
Затем A, B и C используются в качестве начальных значений в функции nls().
(ii) Используйте функцию nls()
nlreg = nls(y ~ (1/b)*y_1 - (a/b)*y_2 - (c/b)*x_1,
start = list(a = A, b = B, c = C))
Результаты можно увидеть с помощью кода:
summary(nlreg)
Спасибо Бену Болкеру за понимание :)
person
SavedByJESUS
schedule
24.02.2013
dynlm) - person Ben Bolker schedule 23.02.2013piиxоба наблюдаемы, то это должно быть легко совместимо сlm(). Единственным аргументом в пользуnls-подгонки будет один из способов получить переменныеa,bиcнапрямую, вместо того, чтобы вычислять их обратно (и использовать что-то вроде дельта-метода для аппроксимации их неопределенностей). Я бы посоветовал вам (1) использоватьlm()в соответствии с моделью; (2) получить начальные значения из подгонкиnlsпутем обратного вычисления этих коэффициентов. Если вам нужна помощь с домашним заданием, вам обязательно придется показать нам, что вы уже пробовали ... - person Ben Bolker schedule 23.02.2013nlsвыше... самый простой способ получить запаздывающие переменные для линейной регрессии - это сделать копии и добавитьNAзначений/обрезать конечные значения соответствующим образом, например отставание-1 отx=c(NA,x[-length(x)])- person Ben Bolker schedule 23.02.2013